AgentCore Runtime Stateful MCPをゼロから理解する——プロトコルの仕組みから実装まで
ハンズオン記事では「何をするか」を中心に書いた。この記事では「なぜそうするのか」に踏み込む。MCPプロトコルの仕組み、SSEストリームの読み方、SigV4署名の役割——これらを理解した上でコードを書くと、エラーが出たときに何が起きているか判断できるようになる。
この記事でわかること
- MCPプロトコル(JSON-RPC + SSE)の仕組み
- AgentCore RuntimeとStateless MCPの違い
- SigV4署名が必要な理由と実装方法
- Progress notifications・Elicitation・Samplingの通信フロー
- 完全コピペで動くサーバー・クライアントコード
MCPプロトコルの基本
MCPはクライアントとサーバーがJSON-RPC 2.0でやり取りするプロトコル。
JSON-RPCはシンプルな規約で、リクエストは以下の形式になる:
{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/call",
"params": {
"name": "my_tool",
"arguments": {}
}
}
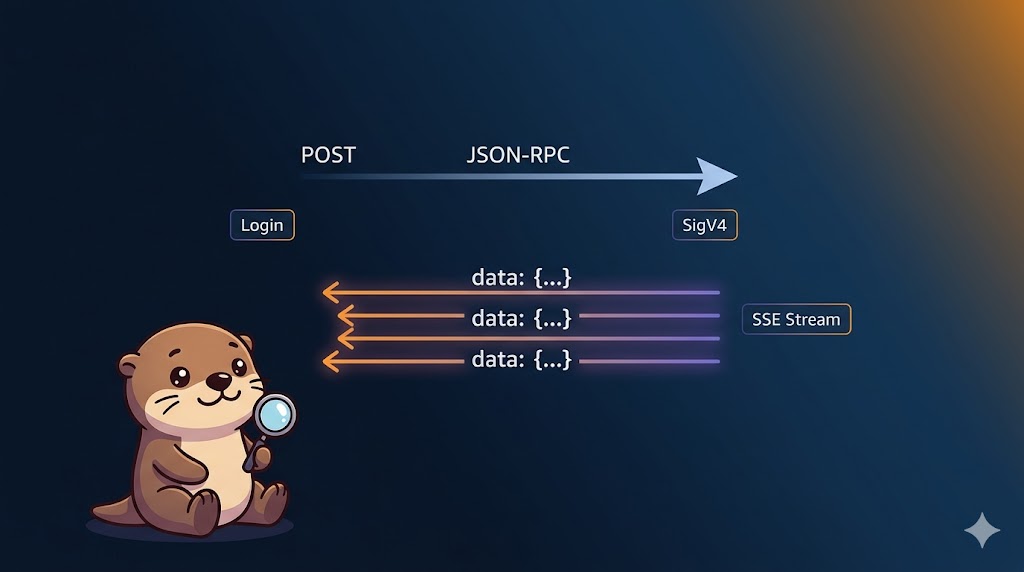
通常のHTTP APIと違うのは、サーバーからクライアントへの非同期メッセージが必要になる。ツールの実行中に進捗を通知したり、追加情報を求めたりする。これを実現するために**SSE(Server-Sent Events)**を使う。
クライアント サーバー
| |
|-- POST /mcp (tools/call) ---------->| ← リクエスト
| |
|<-- HTTP 200 (SSE stream 開始) ------| ← レスポンスヘッダー
| |
|<-- data: {"method":"notifications/ | ← 進捗通知(非同期)
| progress", ...} |
| |
|<-- data: {"result": {...}} | ← 最終結果
AgentCore RuntimeはPOSTリクエストのレスポンスとしてSSEストリームを返す。クライアントはこのストリームを読み続けながら、中間通知(進捗・情報要求・LLM生成依頼)を処理する。
なぜ`invoke_agent_runtime`では動かないか
boto3の invoke_agent_runtime は以下のような動作をする:
POST /runtimes/.../invocations
→ レスポンスをすべて読み込む
→ Pythonオブジェクトとして返す
SSEストリームを返すエンドポイントに対して「すべて読み込む」APIを使うと、ストリームが終わるまで(ツールの実行完了まで)ブロックされる。途中の通知は取得できない。
ElicitationとSamplingはさらに深刻で、サーバーがクライアントにリクエストを送ってくるのを待っているが、クライアントが応答できないためサーバー側がずっと待ち続ける。結果としてタイムアウトになる。
SigV4署名の仕組み
AgentCore RuntimeへのリクエストにはSigV4署名が必要。これはAWSがAPIへの不正アクセスを防ぐための認証方式で、リクエストの内容・タイムスタンプ・AWSクレデンシャルを組み合わせて署名を生成し、HTTPヘッダーに付ける。
boto3の botocore を使うと以下のように実装できる:
import boto3
import botocore.auth
import botocore.credentials
import botocore.awsrequest
session = boto3.Session()
creds = session.get_credentials().get_frozen_credentials()
def sign_request(method, url, body_bytes=None, extra_headers=None):
headers = extra_headers or {}
req = botocore.awsrequest.AWSRequest(
method=method,
url=url,
data=body_bytes,
headers=headers
)
auth = botocore.auth.SigV4Auth(
botocore.credentials.Credentials(
creds.access_key,
creds.secret_key,
creds.token
),
'bedrock-agentcore', # ← サービス名(固定)
'ap-northeast-1' # ← リージョン
)
auth.add_auth(req)
return dict(req.headers)
sign_request() を呼ぶと、Authorization ヘッダーなどが自動的に付加される。あとはこれをそのまま requests.post() に渡せばいい。
エンドポイントURLの構造
AgentCore RuntimeのエンドポイントURLは以下の形式:
https://bedrock-agentcore.{region}.amazonaws.com
/runtimes/{URLエンコードしたRuntimeARN}
/invocations
?qualifier={エンドポイント名}
URLエンコードが必要な理由は、RuntimeARNに : や / が含まれているため。そのままURLに入れるとパスとして解釈されてしまう。
import urllib.parse
runtime_arn = 'arn:aws:bedrock-agentcore:ap-northeast-1:123456789012:runtime/my_runtime-AbCdEf'
encoded_arn = urllib.parse.quote(runtime_arn, safe='')
# → 'arn%3Aaws%3Abedrock-agentcore%3Aap-northeast-1%3A123456789012%3Aruntime%2Fmy_runtime-AbCdEf'
base_url = f'https://bedrock-agentcore.ap-northeast-1.amazonaws.com/runtimes/{encoded_arn}/invocations?qualifier=demo_endpoint'
MCPセッションの確立
MCPにはハンドシェイクがある。最初に initialize を送ってサーバーとプロトコルバージョンをネゴシエーションし、次に notifications/initialized を送って準備完了を通知する。
import json, requests
def mcp_post(body_dict, session_id=None, stream=False):
body = json.dumps(body_dict).encode()
extra = {
'Content-Type': 'application/json',
'Accept': 'application/json, text/event-stream',
'mcp-protocol-version': '2025-03-26',
}
if session_id:
extra['Mcp-Session-Id'] = session_id
headers = sign_request('POST', base_url, body, extra)
return requests.post(base_url, data=body, headers=headers, timeout=60, stream=stream)
# ハンドシェイク
resp = mcp_post({
'jsonrpc': '2.0',
'id': 1,
'method': 'initialize',
'params': {
'protocolVersion': '2025-03-26',
'capabilities': {
'sampling': {}, # ← Samplingを受け付けることをサーバーに伝える
'elicitation': {} # ← Elicitationを受け付けることをサーバーに伝える
},
'clientInfo': {'name': 'my-client', 'version': '1.0'}
}
})
# セッションIDはレスポンスヘッダーから取得
session_id = resp.headers.get('Mcp-Session-Id')
# 初期化完了を通知
mcp_post({'jsonrpc': '2.0', 'method': 'notifications/initialized'}, session_id)
capabilities に sampling や elicitation を入れておくことで、サーバーはこれらの機能をクライアントが処理できると判断する。入れないとサーバーが機能を使おうとしたときにエラーになる。
Progress notificationsの仕組み
ツールを呼び出すときに _meta.progressToken を付けると、サーバーがそのトークンを使って進捗通知を送り返してくる。
クライアント サーバー
| |
|-- POST tools/call (_meta.progressToken) -->|
| | サーバーがツール実行開始
|<-- data: {"method":"notifications/ |
| progress", "params": { |
| "progressToken": "p1", |
| "progress": 1, "total": 4, |
| "message": "データ取得中"}} |
| |
|<-- data: {"method":"notifications/ |
| progress", "params": { |
| "progress": 2, ...}} |
| |
|<-- data: {"result": {"content": [...]}} | ← 最終結果
resp = mcp_post({
'jsonrpc': '2.0', 'id': 2,
'method': 'tools/call',
'params': {
'name': 'long_task',
'arguments': {},
'_meta': {'progressToken': 'progress-1'} # ← 任意の文字列
}
}, session_id, stream=True)
for chunk in resp.iter_lines():
if chunk:
line = chunk.decode('utf-8')
if line.startswith('data:'):
data = json.loads(line[5:].strip())
if data.get('method') == 'notifications/progress':
p = data['params']
print(f"[{int(p['progress'])}/{int(p['total'])}] {p.get('message', '')}")
elif 'result' in data:
print(f"完了: {data['result']['content'][0]['text']}")
実際の出力例:
[1/4] データ取得中
[2/4] 解析中
[3/4] 集計中
[4/4] 完了
完了: すべてのステップが完了しました
Elicitationの仕組み
Elicitationはサーバーからクライアントへのリクエスト。サーバーが elicitation/create を送り、クライアントがユーザーに質問して応答を返す。
クライアント サーバー
| |
|-- POST tools/call (book_flight) ---------->|
| | サーバーがelicit()を呼ぶ
|<-- data: {"method":"elicitation/create", |
| "id": "elicit-1", |
| "params": { |
| "message": "旅行の情報を...", |
| "requestedSchema": {...}}} |
| | サーバーはここで待機
|-- POST (elicit-1への応答) --------------->|
| {"id":"elicit-1","result":{ |
| "action":"accept", |
| "content":{"departure":"東京",...}}} |
| | サーバーが処理を再開
|<-- data: {"result": {"content": [...]}} |
なぜ別スレッドが必要か:ツールの呼び出し(SSEストリームの読み取り)と、Elicitationへの応答(新しいPOST)を同時に行う必要があるため。メインスレッドでSSEを読みながら、サブスレッドから応答POSTを送る、という構造になる。
import threading, queue
events_q = queue.Queue()
def call_tool():
resp = mcp_post({
'jsonrpc': '2.0', 'id': 3,
'method': 'tools/call',
'params': {'name': 'book_flight', 'arguments': {}}
}, session_id, stream=True)
for chunk in resp.iter_lines():
if chunk:
line = chunk.decode('utf-8')
if line.startswith('data:'):
events_q.put(json.loads(line[5:].strip()))
# ツール呼び出しをバックグラウンドで実行
t = threading.Thread(target=call_tool, daemon=True)
t.start()
# elicitation/create を待つ
elicitation_id = None
while True:
event = events_q.get(timeout=10)
if event.get('method') == 'elicitation/create':
elicitation_id = event['id']
print(f"サーバーからの質問: {event['params']['message']}")
# スキーマを確認してユーザーに入力を促す
print(f"入力項目: {list(event['params']['requestedSchema']['properties'].keys())}")
break
elif 'result' in event or 'error' in event:
break # 直接結果が返ってきた場合
# ユーザー入力をサーバーに返す
if elicitation_id:
mcp_post({
'jsonrpc': '2.0',
'id': elicitation_id,
'result': {
'action': 'accept', # または 'decline'(キャンセル)
'content': {'departure': '東京', 'destination': 'ニューヨーク'}
}
}, session_id)
# 最終結果を受け取る
result = events_q.get(timeout=10)
print(f"結果: {result['result']['content'][0]['text']}")
t.join(timeout=5)
実際の出力例:
サーバーからの質問: 旅行の情報を入力してください
入力項目: ['departure', 'destination']
結果: 予約受付: 東京 → ニューヨーク
Samplingの仕組み
SamplingはElicitationに似た仕組みで、サーバーがクライアントにLLMの呼び出しを依頼する。
クライアント サーバー
| |
|-- POST tools/call (generate_summary) ----->|
| | サーバーがctx.sample()を呼ぶ
|<-- data: {"method":"sampling/ |
| createMessage", |
| "id": "sample-1", |
| "params": { |
| "messages": [...], |
| "maxTokens": 100}} |
| | サーバーはここで待機
| クライアントがLLMを呼ぶ(Bedrock等) |
|-- POST (sample-1への応答) --------------->|
| {"id":"sample-1","result":{ |
| "role":"assistant", |
| "content":{"type":"text","text":"..."}}}|
| | サーバーがLLM結果を使って処理
|<-- data: {"result": {"content": [...]}} |
events_q2 = queue.Queue()
def call_sampling():
resp = mcp_post({
'jsonrpc': '2.0', 'id': 4,
'method': 'tools/call',
'params': {'name': 'generate_summary', 'arguments': {'topic': 'Machine Learning'}}
}, session_id, stream=True)
for chunk in resp.iter_lines():
if chunk:
line = chunk.decode('utf-8')
if line.startswith('data:'):
events_q2.put(json.loads(line[5:].strip()))
t2 = threading.Thread(target=call_sampling, daemon=True)
t2.start()
# sampling/createMessage を待つ
event = events_q2.get(timeout=10)
if event.get('method') == 'sampling/createMessage':
sampling_id = event['id']
prompt = event['params']['messages'][0]['content']['text']
print(f"LLM生成依頼: {prompt}")
# クライアント側でLLMを呼び出す
bedrock = boto3.client('bedrock-runtime', region_name='ap-northeast-1')
br_resp = bedrock.converse(
modelId='jp.anthropic.claude-haiku-4-5-20251001-v1:0',
messages=[{'role': 'user', 'content': [{'text': prompt}]}]
)
generated = br_resp['output']['message']['content'][0]['text']
# 生成結果をサーバーに返す
mcp_post({
'jsonrpc': '2.0',
'id': sampling_id,
'result': {
'role': 'assistant',
'content': {'type': 'text', 'text': generated},
'model': 'claude-haiku-4-5',
'stopReason': 'endTurn'
}
}, session_id)
# 最終結果
result = events_q2.get(timeout=10)
print(f"結果: {result['result']['content'][0]['text']}")
t2.join(timeout=5)
サーバーのコード(FastMCP 3.1.1)
# server.py
import sys, os
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'lib'))
from fastmcp import FastMCP, Context
from pydantic import BaseModel
import asyncio
mcp = FastMCP("stateful-mcp-demo")
@mcp.tool()
async def long_task(ctx: Context) -> str:
steps = ["データ取得中", "解析中", "集計中", "完了"]
for i, step in enumerate(steps, 1):
await ctx.report_progress(progress=i, total=len(steps), message=step)
await asyncio.sleep(1)
return "すべてのステップが完了しました"
class TravelInfo(BaseModel):
departure: str
destination: str
@mcp.tool()
async def book_flight(ctx: Context) -> str:
result = await ctx.elicit(
message="旅行の情報を入力してください",
response_type=TravelInfo
)
if result.action == "accept":
return f"予約受付: {result.data.departure} → {result.data.destination}"
return "キャンセルされました"
@mcp.tool()
async def generate_summary(ctx: Context, topic: str) -> str:
result = await ctx.sample(f"{topic}を一言で説明して", max_tokens=100)
return result.text
if __name__ == "__main__":
mcp.run(
transport="streamable-http",
host="0.0.0.0", # ← 必須。0.0.0.0でないとAgentCoreから届かない
stateless_http=False, # ← 必須。TrueにするとSSEが機能しない
)
デプロイ手順(まとめ)
1. ARM64向けパッケージをビルド
mkdir -p /tmp/agentcore-demo && cd /tmp/agentcore-demo
cp /path/to/server.py .
mkdir -p lib
pip install fastmcp \
--target ./lib \
--platform manylinux2014_aarch64 \
--python-version 3.12 \
--only-binary=:all:
zip -r deployment.zip server.py lib/
--platform manylinux2014_aarch64 を省くと、x86_64向けの .so ファイルが入りデプロイ後に起動失敗する。
2. S3にアップロード
aws s3 cp deployment.zip s3://your-bucket/agentcore/deployment.zip
3. IAMロール作成
import boto3, json, time
iam = boto3.client('iam')
trust = {
'Version': '2012-10-17',
'Statement': [
{'Effect': 'Allow', 'Principal': {'Service': 'bedrock.amazonaws.com'}, 'Action': 'sts:AssumeRole'},
{'Effect': 'Allow', 'Principal': {'Service': 'bedrock-agentcore.amazonaws.com'}, 'Action': 'sts:AssumeRole'},
]
}
role = iam.create_role(RoleName='agentcore-demo-role', AssumeRolePolicyDocument=json.dumps(trust))
iam.attach_role_policy(RoleName='agentcore-demo-role', PolicyArn='arn:aws:iam::aws:policy/AmazonBedrockFullAccess')
iam.attach_role_policy(RoleName='agentcore-demo-role', PolicyArn='arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess')
time.sleep(10) # IAM伝播を待つ
bedrock-agentcore.amazonaws.com が必要な理由:AgentCore Runtimeがロールを引き受けてコードを実行するサービスプリンシパルがこれだから。bedrock.amazonaws.com だけでは権限が足りない。
4. Runtimeとエンドポイント作成
control = boto3.client('bedrock-agentcore-control', region_name='ap-northeast-1')
runtime = control.create_agent_runtime(
agentRuntimeName='stateful_mcp_demo', # ハイフン不可。[a-zA-Z][a-zA-Z0-9_]{0,47}
agentRuntimeArtifact={'codeConfiguration': {
'code': {'s3': {'bucket': 'your-bucket', 'prefix': 'agentcore/deployment.zip'}},
'runtime': 'PYTHON_3_12',
'entryPoint': ['server.py'],
}},
networkConfiguration={'networkMode': 'PUBLIC'},
roleArn=role['Role']['Arn'],
protocolConfiguration={'serverProtocol': 'MCP'},
)
runtime_id = runtime['agentRuntimeId']
# READY待ち(数分)
while True:
r = control.get_agent_runtime(agentRuntimeId=runtime_id)
if r['status'] == 'READY': break
time.sleep(15)
# エンドポイント作成
control.create_agent_runtime_endpoint(agentRuntimeId=runtime_id, name='demo_endpoint')
while True:
r = control.get_agent_runtime_endpoint(agentRuntimeId=runtime_id, endpointName='demo_endpoint')
if r['status'] == 'READY': break
time.sleep(15)
CloudWatch Logsでデバッグ
デプロイに失敗したりツールが動かない場合はCloudWatch Logsを確認する。ロググループは自動作成される。
aws logs tail /aws/bedrock-agentcore/runtime/stateful_mcp_demo \
--follow \
--region ap-northeast-1
よくあるエラーと原因:
| エラー | 原因 |
|---|---|
incompatible with Linux ARM64 |
x86_64バイナリが混入。--platform manylinux2014_aarch64 でビルドし直す |
Connection refused |
host="127.0.0.1"のまま。host="0.0.0.0" に変更 |
ModuleNotFoundError |
lib/が正しくZIPに含まれていない。sys.path.insert を確認 |
| タイムアウト(起動時) | pip installが起動時に走っている。パッケージをZIPにバンドルする |
まとめ
AgentCore RuntimeのStateful MCPは、MCPのJSON-RPCプロトコルをHTTP+SSEで実装したもの。
- SSEストリーム:POSTのレスポンスとして届く。
iter_lines()で読み続ける - Progress notifications:
progressToken付きのtools/callに対してnotifications/progressが流れてくる - Elicitation:SSEストリームに
elicitation/createが来る。別スレッドから新しいPOSTで応答する - Sampling:SSEストリームに
sampling/createMessageが来る。クライアント側でLLMを呼んで応答する
仕組みがわかれば、エラーが出たときにどこを直せばいいか判断しやすくなる。