【CCA Foundations対策 / Claude API編 #5】Evalの実装——データセット生成・実行・採点
Anthropic Academyの「Claude APIを使用した構築」コースをもとに解説しています。
前回(#4)でEvalのワークフローと5ステップを整理した。この記事では実際にコードを書いてパイプラインを動かす。テストデータの自動生成から、実行・採点まで一通り実装する。
テストデータセットを自動生成する
Evalに必要なテストデータは手動で作ることもできるが、Claudeに生成させると大量のケースをすばやく用意できる。
手動作成 vs 自動生成の使い分け
| 方法 | 向いているケース |
|---|---|
| 手動作成 | 実際のユーザー入力パターン・必ず通過させたいエッジケース |
| 自動生成 | 多様なバリエーションの網羅・大量のケースを素早く用意したい |
手動作成は少数精鋭で使う。実際のユーザーが送ってきそうな典型的な入力や、バグが出やすいコーナーケースを厳選してデータセットに含める。
自動生成は多様性と量の確保に向いている。Claudeに多数のバリエーションを生成させることで、手動では思いつかないパターンをカバーできる。どちらか一方ではなく、両方を組み合わせるのが実践的なアプローチ。
今回の例題は「テキスト処理ツール」——ユーザーのリクエストに対してPython・JSON・正規表現のいずれかを返すプロンプトを評価する。
generate_dataset() の実装
import anthropic
import json
from dotenv import load_dotenv
load_dotenv()
client = anthropic.Anthropic()
model = "claude-haiku-4-5-20251001" # データ生成にはHaikuで十分
def add_user_message(messages, text):
messages.append({"role": "user", "content": text})
def add_assistant_message(messages, text):
messages.append({"role": "assistant", "content": text})
def chat(messages, system=None, temperature=1.0, stop_sequences=[]):
params = {
"model": model,
"max_tokens": 1000,
"messages": messages,
"temperature": temperature,
}
if system:
params["system"] = system
if stop_sequences:
params["stop_sequences"] = stop_sequences
response = client.messages.create(**params)
return response.content[0].text
FENCE = "```" # プリフィル・ストップシーケンスで使うトリプルバッククォート
def generate_dataset():
prompt = f"""
テキスト処理ツールのEvalデータセットを生成してください。
このツールはユーザーのリクエストに対して、Python関数・JSON・正規表現のいずれかを返します。
以下の形式でJSON配列を出力してください:
{FENCE}json
[
{{
"task": "タスクの説明",
"format": "python" または "json" または "regex"
}}
]
{FENCE}
条件:
- 1つの関数・1つのJSONオブジェクト・1つの正規表現で解決できるシンプルなタスク
- python・json・regexをそれぞれ1件以上含める
3件のタスクを生成してください。
"""
messages = []
add_user_message(messages, prompt)
add_assistant_message(messages, f"{FENCE}json") # プリフィル
text = chat(messages, stop_sequences=[FENCE]) # 閉じ ``` で停止
return json.loads(text)
ポイントは2つ:
FENCE変数でトリプルバッククォートを一元管理(Markdownのコードブロックと衝突しないための工夫)- プリフィルで
```jsonを先置き → Claudeはその続きからJSONの中身だけを生成 → ストップシーケンスで閉じ```手前で停止(#3で扱ったテクニック)
実行するとこんなデータセットが得られる:
dataset = generate_dataset()
print(dataset)
[
{"task": "メールアドレスを検証するPython関数を書いてください", "format": "python"},
{"task": "名前・年齢・役職を含む社員情報をJSON形式で作成してください", "format": "json"},
{"task": "日本の郵便番号(000-0000形式)にマッチする正規表現を書いてください", "format": "regex"}
]
生成されたデータセットはファイルに保存しておく:
with open("dataset.json", "w", encoding="utf-8") as f:
json.dump(dataset, f, indent=2, ensure_ascii=False)
Evalパイプラインを走らせる
データセットができたら、プロンプトと組み合わせてClaudeに回答させ、結果を収集する。パイプラインは3つの関数で構成する。
3つのコア関数
# 評価対象のプロンプト(v1)
PROMPT_TEMPLATE = """
以下のタスクを解決してください:
{task}
"""
def run_prompt(test_case):
"""テストケースとプロンプトをマージしてClaudeに送る"""
prompt = PROMPT_TEMPLATE.format(task=test_case["task"])
messages = []
add_user_message(messages, prompt)
return chat(messages)
def run_test_case(test_case):
"""1件のテストケースを実行して採点する"""
output = run_prompt(test_case)
score = 10 # ← この時点ではハードコード(後で本実装に差し替える)
return {
"output": output,
"test_case": test_case,
"score": score,
}
def run_eval(dataset):
"""データセット全件を実行して結果を収集する"""
results = []
for test_case in dataset:
result = run_test_case(test_case)
results.append(result)
return results
実行してみると、v1プロンプトでのClaudeの出力がわかる:
with open("dataset.json", "r", encoding="utf-8") as f:
dataset = json.load(f)
results = run_eval(dataset)
print(results[0]["output"])
v1では説明文とコードブロックが混在した出力が返ってくる:
メールアドレスを検証するPython関数の実装例です。
(コードブロック)
import re
def validate_email(email: str) -> bool:
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
return bool(re.match(pattern, email))
(コードブロック終わり)
この関数は...(説明が続く)
このままではコードとして使えない。スコアも 10 のハードコードのままで意味がない——次のセクションで採点を実装する。
score = 10 をハードコードしている理由は、グレーダーより先にパイプライン全体の動作を確認するため。最初から全部を実装しようとすると複雑になる。まずデータ生成・プロンプト実行・結果収集の流れが正しく動くことを確認してから、グレーダーを独立したステップとして追加していく。
モデルベースの採点
グレーダーには3種類ある:
| 種類 | 方法 | 向いているタスク |
|---|---|---|
| コードベース | プログラムで検証 | 構文チェック・形式検証 |
| モデルベース | 別のClaudeで評価 | 品質・指示への忠実さ |
| 人手 | 人が直接採点 | 総合的な判断が必要なもの |
まずモデルベースのグレーダーを実装する。
grade_by_model() の実装
def grade_by_model(test_case, output):
eval_prompt = f"""
あなたはコードレビューの専門家です。以下のAI生成コードを評価してください。
タスク:{test_case["task"]}
出力:{output}
以下の形式でJSONを返してください:
- "strengths": 優れている点(1〜3個の配列)
- "weaknesses": 改善できる点(1〜3個の配列)
- "reasoning": 評価の理由(簡潔に)
- "score": 1〜10の評価スコア
"""
messages = []
add_user_message(messages, eval_prompt)
add_assistant_message(messages, f"{FENCE}json") # プリフィル
text = chat(messages, stop_sequences=[FENCE])
return json.loads(text)
「スコアだけ聞くと中間値に偏る」問題
グレーダーに score だけ返させると、モデルは迷ったときに 6 や 7 あたりを返しがちになる。strengths・weaknesses・reasoning も一緒に求めることで、採点の根拠を言語化させてから数値を出すよう促せる。
run_test_case に組み込む
from statistics import mean
def run_test_case(test_case):
output = run_prompt(test_case)
grade = grade_by_model(test_case, output)
return {
"output": output,
"test_case": test_case,
"score": grade["score"],
"reasoning": grade["reasoning"],
}
def run_eval(dataset):
results = []
for test_case in dataset:
result = run_test_case(test_case)
results.append(result)
avg = mean([r["score"] for r in results])
print(f"平均スコア: {avg:.1f}")
return results
v1プロンプトで実行すると、説明文が混入しているのでスコアが低めになる:
平均スコア: 5.7
コードベースの採点
モデルベースの採点だけでは「内容の品質」しか測れない。生成されたコードが実際に構文として正しいかどうかは、プログラムで検証する方が確実。
構文バリデーション関数
import ast
import re
def validate_json(text):
try:
json.loads(text.strip())
return 10
except json.JSONDecodeError:
return 0
def validate_python(text):
try:
ast.parse(text.strip())
return 10
except SyntaxError:
return 0
def validate_regex(text):
try:
re.compile(text.strip())
return 10
except re.error:
return 0
def grade_syntax(output, test_case):
fmt = test_case.get("format", "")
if fmt == "json":
return validate_json(output)
elif fmt == "python":
return validate_python(output)
elif fmt == "regex":
return validate_regex(output)
return 0
各関数はパースを試みて、成功なら 10、失敗なら 0 を返す。「ほぼ正しい」は存在しない——構文として動くかどうかのバイナリ判定。
モデルスコアと合算する
モデルスコアは「タスクの要件を満たしているか・回答の質」を測り、コードスコアは「構文として正しく動くか」を測る。どちらか片方だけでは不十分——内容は良くても構文エラーのコードは使えないし、構文は正しくてもタスクを満たさないコードも意味がない。2つを平均することで、品質と技術的な正確さを両面から評価できる。
def run_test_case(test_case):
output = run_prompt(test_case)
grade = grade_by_model(test_case, output)
model_score = grade["score"]
syntax_score = grade_syntax(output, test_case)
final_score = (model_score + syntax_score) / 2
return {
"output": output,
"test_case": test_case,
"score": final_score,
"model_score": model_score,
"syntax_score": syntax_score,
"reasoning": grade["reasoning"],
}
v1プロンプトは説明文が混じるので構文スコアが低くなる。final = (model_score + syntax_score) / 2 で内容と構文を等ウェイトで合算している:
メールアドレス(python)→ model: 6 / syntax: 0 → final: 3.0
※説明文がついているのでast.parseが失敗する
社員情報(json) → model: 7 / syntax: 0 → final: 3.5
※コードブロック記法が残っているのでjson.loadsが失敗する
郵便番号(regex) → model: 8 / syntax: 10 → final: 9.0
※正規表現はシンプルなので混入が少ない
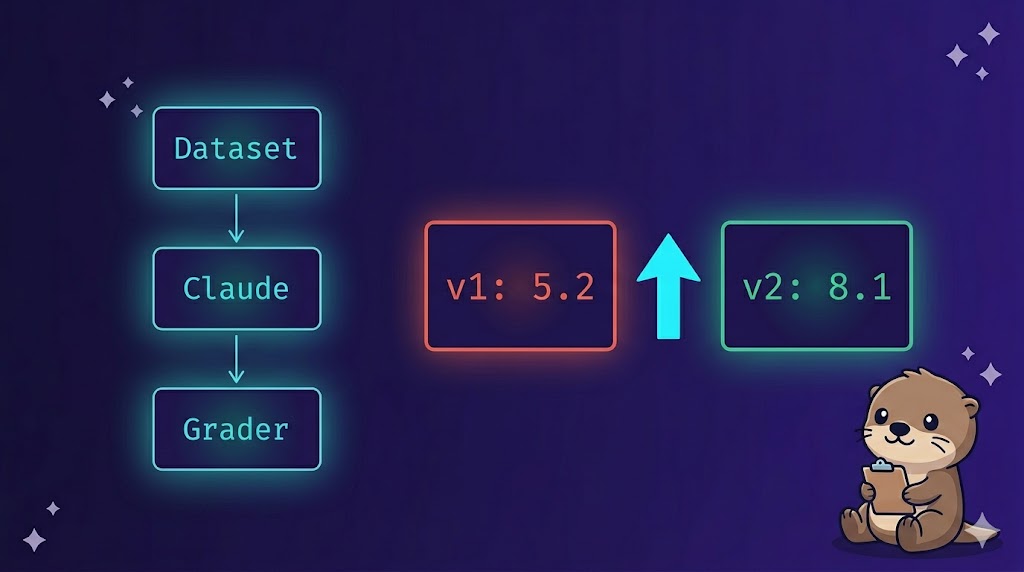
平均スコア v1: 5.2
プロンプトを改善してv2のスコアと比較する
v1の問題点は「説明文とコードブロック記法が混入すること」。プロンプトに明示的な指示とプリフィルを加える:
def run_prompt(test_case):
prompt = f"""
以下のタスクを解決してください:
{test_case["task"]}
* Python・JSON・正規表現のいずれかのみを返してください
* 説明・コメント・コードブロック記法は不要です
"""
messages = []
add_user_message(messages, prompt)
add_assistant_message(messages, f"{FENCE}code\n") # プリフィルでコードから始める
return chat(messages, stop_sequences=[FENCE])
平均スコア v2: 8.1 (v1: 5.2 → +2.9)
数値でプロンプトの改善を確認できた。「v2の方が良さそう」という感覚ではなく、スコアという根拠を持って次の判断ができる。
まとめ
- テストデータはClaudeで自動生成できる。Haikuを使うとコストを抑えられる
- パイプラインの核は
run_prompt/run_test_case/run_evalの3関数 - モデルベース採点では強み・弱み・理由もセットで求めると採点の精度が上がる
- コードベース採点は構文の正しさをバイナリで検証する(10 or 0)
- 両スコアを合算することで「内容の品質」と「技術的な正確さ」を両面から評価できる
- スコアを比較することでプロンプトの改善が数値で見える
次回はEvalで品質を測る前提となる、プロンプトの書き方を体系的に整理する——明確さ・具体性・XMLタグ・マルチショットの4つのテクニックを扱う。