GenUのRAGに部署別アクセス制御を追加した——Bedrock Knowledge Base メタデータフィルタリング
検証の目的
前回の記事でGenUを閉域ネットワークにデプロイした。今回はその閉域GenU環境内で以下の2点を証明する。
- 部署別アクセス制御をAPIベースで実現できる:閉域VPC内のカスタムLambdaをPrivate API Gateway経由で呼び出すことで、既存システムからもフィルタリング付きでBedrockにアクセスできる
- GenUチャットとAPI経由のアクセスが同一環境に共存できる:GenUのチャット画面と既存システムからのAPI呼び出しが、同じKnowledge Base・同じCognito認証・同じ閉域VPCを共有しながら成立する
| アクセス経路 | 想定利用者 |
|---|---|
| GenUチャット画面 | 社員がブラウザから使う |
| API(カスタムLambda) | 既存の社内システムから呼び出す |
課題:GenU標準RAGはアクセス制御ができない
GenUのRAGチャット(Knowledge Base)は、すべてのユーザーがKnowledge Base内の全ドキュメントを検索できる仕組み。
「部署ごとに参照できるドキュメントを制限したい」という要件がある場合、標準機能では対応不可。
実際にGenUのRAGチャットで確認すると、営業部ユーザーでログインしても人事部のドキュメントが返ってくる状態。
| ユーザー | 質問 | 返ってくる回答 |
|---|---|---|
| 営業部ユーザー | 有給休暇は何日? | 人事部_規程.txt の内容 ❌ |
| 営業部ユーザー | 経費精算の上限は? | 営業部_規程.txt の内容 ✅ |
解決策:メタデータフィルタリング
Bedrock Knowledge Baseにはメタデータフィルタリングという機能がある。ドキュメントに department: 営業部 のようなメタデータを付与しておき、検索時にフィルター条件を指定することで特定のドキュメントのみを検索対象にできる仕組み。
メタデータフィルタリングのイメージ
図書館に例えると、本棚に「営業部用」「開発部用」というラベルを貼っておき、検索時に「営業部用のラベルが貼ってある本だけを探して」と指定するようなイメージ。ラベル(メタデータ)がないと全部の本が検索対象になってしまう。
【フィルターなし】 営業部ユーザーが「有給は何日?」と質問
→ 全ドキュメントを検索 → 人事部_規程.txt がヒット → 情報が漏れる ❌
【フィルターあり】 営業部ユーザーが「有給は何日?」と質問
→ department=営業部 のドキュメントだけ検索 → ヒットなし → 「回答できません」 ✅
GenUの標準RAGチャットはこのフィルタリングを使っていないため、カスタムLambdaを追加する構成で対応。
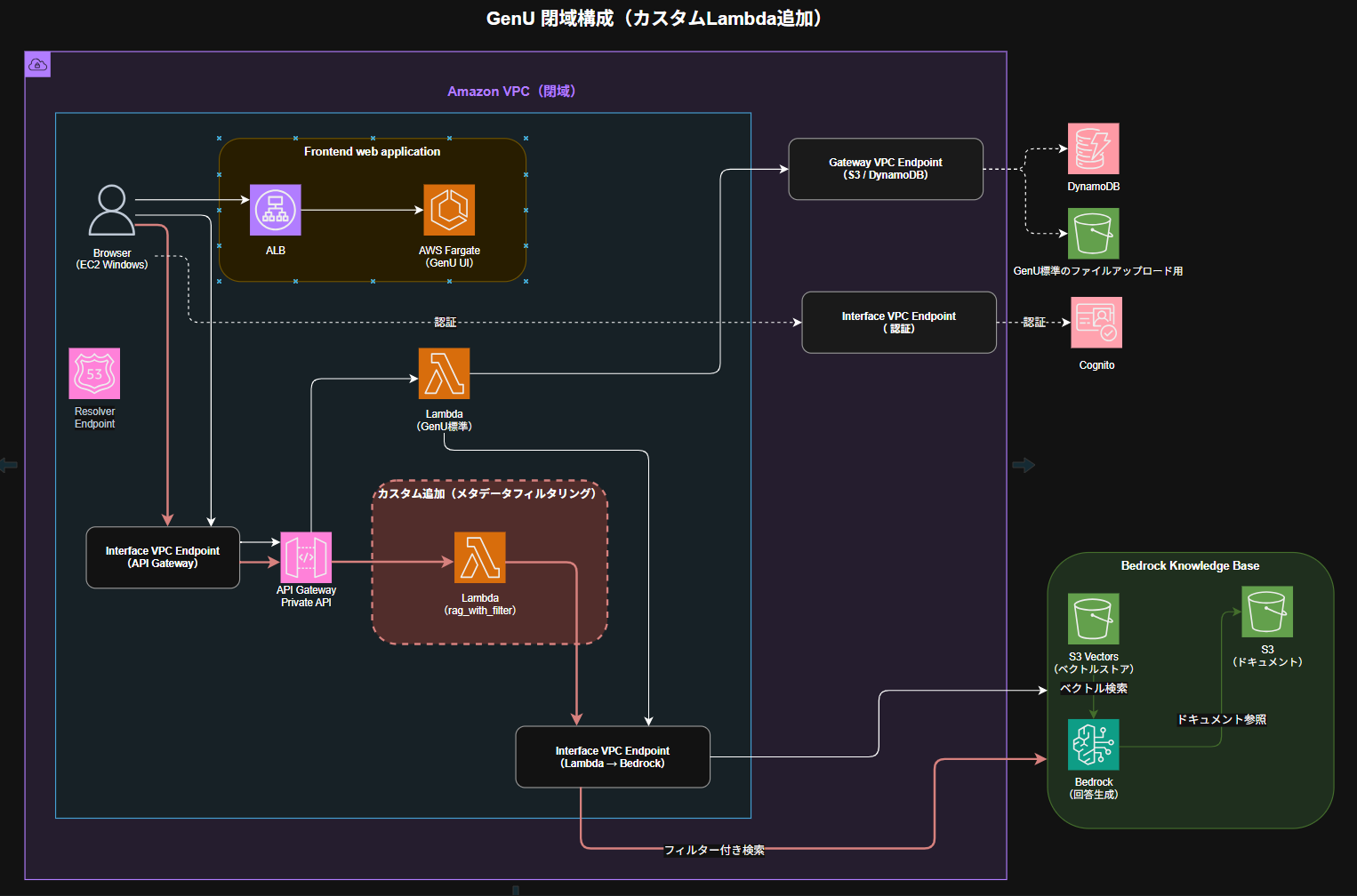
【今回の構成】
ユーザー(Cognitoログイン済み)
↓ JWTトークン(custom:department属性を含む)
API Gateway(Cognitoオーソライザーで署名検証)
↓
Lambda(rag_with_filter.py)
↓ JWTから部署を取得してフィルター条件を生成
Bedrock RetrieveAndGenerate API
↓ 該当部署のドキュメントのみ検索
Bedrock Claude(回答生成)
なぜGenUのLambdaを改修しなかったのか
GenUのRAG処理を担うLambdaを直接改修してフィルタリングを追加する方法もある。JWTトークンから部署情報を取得してKB検索にフィルターを渡すだけなので、実装としては単純。
ただしこのアプローチには問題がある。
- GenUのアップデートへの追従が難しくなる:GenU本体のコードを改変すると、GenUがアップデートされるたびに改変箇所をマージし直す作業が発生する
- OSSの改変:GenUはAWS公式のOSSのため、本体コードへの改変はできるだけ避けたい
今回はGenUのコードに一切手を加えず、カスタムLambdaをGenUのインフラに追加する形を採用。GenUのアップデートに影響されない独立した構成になっている。
GenUのチャット画面からフィルタリングを使えるようにしたい場合は、GenUがサポートしているAgentCore Runtime(Experimentalタブ)経由で実装する方法がある。この場合もGenUの本体コードには手を加えない。
ドキュメントの準備
S3にメタデータ付きでアップロード
各ドキュメントと同名の .metadata.json ファイルをS3に一緒に配置。
s3://genu-kb-docs/
営業部_規程.txt
営業部_規程.txt.metadata.json
開発部_規程.txt
開発部_規程.txt.metadata.json
人事部_規程.txt
人事部_規程.txt.metadata.json
メタデータファイルの中身:
{
"metadataAttributes": {
"department": "営業部"
}
}
Lambda の実装
retrieve_and_generate APIを使い、メタデータフィルターを付けてKBに問い合わせる構成。
def query_with_filter(query: str, department: str) -> dict:
region = os.environ.get("AWS_REGION", "ap-northeast-1")
knowledge_base_id = os.environ["KNOWLEDGE_BASE_ID"]
model_arn = f"arn:aws:bedrock:{region}::foundation-model/anthropic.claude-3-haiku-20240307-v1:0"
client = boto3.client("bedrock-agent-runtime", region_name=region)
response = client.retrieve_and_generate(
input={"text": query},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": knowledge_base_id,
"modelArn": model_arn,
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": 5,
"filter": {
"equals": {
"key": "department",
"value": department,
}
},
}
},
},
},
)
answer = response["output"]["text"]
citations = []
for citation in response.get("citations", []):
for ref in citation.get("retrievedReferences", []):
citations.append({
"text": ref.get("content", {}).get("text", ""),
"location": ref.get("location", {}),
})
return {"answer": answer, "citations": citations}
JWT と Cognito オーソライザーの仕組み
JWT(JSON Web Token)はログイン後にユーザーへ渡される「デジタル身分証明書」。以下の3パーツで構成されている。
ヘッダー.ペイロード.署名
ペイロード部分には { "custom:department": "営業部", "sub": "user-id-xxx" } のようなユーザー情報が入っている。
| 処理 | 内容 | 担当 |
|---|---|---|
| 検証 | このJWTは本物か?改ざんされていないか? | API Gateway(Cognitoオーソライザー) |
| デコード | JWTの中身(部署情報)を読み取る | Lambda |
API Gatewayがすでに「本物のJWT」であることを確認済みのため、Lambdaまで届いたリクエストは「認証済み」が保証されている。LambdaはJWTの中身を読むだけでよく、改めて署名検証をする必要がない。
JWT検証はAPI GatewayのCognitoオーソライザーが実施済みのため、LambdaはJWTをデコードするだけで部署情報を取得可能。
def get_department_from_token(auth_header: str) -> Optional[str]:
token = auth_header.replace("Bearer ", "")
payload_b64 = token.split(".")[1]
payload_b64 += "=" * (4 - len(payload_b64) % 4)
claims = json.loads(base64.b64decode(payload_b64))
return claims.get("custom:department")
CDKでデプロイ
カスタムLambdaとAPI GatewayをCDKでデプロイ。LambdaをVPC内に置く理由は、閉域VPCからBedrockのVPCエンドポイントに到達するため。VPC外のLambdaはVPCエンドポイントを経由できない。PRIVATE_ISOLATED サブネットを明示的に指定。
const ragLambda = new lambda.Function(this, "RagWithFilterLambda", {
functionName: "rag-with-filter",
runtime: lambda.Runtime.PYTHON_3_12,
code: lambda.Code.fromAsset("../lambda"),
handler: "rag_with_filter.handler",
vpc,
vpcSubnets: { subnetType: ec2.SubnetType.PRIVATE_ISOLATED },
environment: {
KNOWLEDGE_BASE_ID: knowledgeBaseId,
},
timeout: cdk.Duration.seconds(30),
memorySize: 256,
});
API GatewayにCognitoオーソライザーを付けることで、JWTの署名検証をAPI Gatewayに委譲。
cdk deploy CustomRagStack \
--context vpcId=<VPC ID> \
--context userPoolId=<CognitoユーザープールID> \
--context knowledgeBaseId=<Knowledge Base ID>
動作確認
Pythonスクリプトで3部署のユーザーがそれぞれの部署の質問をした結果:
--- sales@test.example.com ---
認証: [OK] 部署: 営業部
回答: 接待費は1人あたり1万円が上限として設定されています
引用件数: 1件(営業部_規程.txt)
フィルタリング: [OK] 正常
--- dev@test.example.com ---
認証: [OK] 部署: 開発部
回答: 本番リリースは毎週水曜日のみ行うことができます
引用件数: 1件(開発部_規程.txt)
フィルタリング: [OK] 正常
--- hr@test.example.com ---
認証: [OK] 部署: 人事部
回答: 入社6ヶ月後に10日の有給休暇が付与されます
引用件数: 1件(人事部_規程.txt)
フィルタリング: [OK] 正常
NGケース(営業部ユーザーが他部署の質問をした場合):
=== 営業部ユーザーが人事部の質問 ===
回答: Sorry, I am unable to assist you with this request.
引用件数: 0件
=== 営業部ユーザーが開発部の質問 ===
回答: Sorry, I am unable to assist you with this request.
引用件数: 0件
引用件数が0件になっており、フィルターで他部署のドキュメントが完全にブロックされている状態。
ハマりポイント
モデルARNにクロスリージョンプロファイルは使えない
そもそもなぜLambdaにmodelARNを書くのか
Knowledge Baseの設定画面でもモデルを選ぶ箇所があるため混乱しやすいが、Knowledge Baseに設定するモデルと、Lambda(retrieve_and_generate API)で指定するモデルは別物。
| モデル | 役割 | 設定場所 |
|---|---|---|
| 埋め込みモデル(Titan など) | ドキュメントをベクトル化して検索インデックスを作る | Knowledge Baseの設定 |
| 生成モデル(Claude など) | 検索結果をもとに回答文を生成する | Lambda のAPI呼び出し時に指定 |
retrieve_and_generate API は「Knowledge Baseで検索する」と「モデルで回答を生成する」を1回のAPIで行う設計になっており、リクエストの中に「どのモデルで生成するか」を都度指定する必要がある。
クロスリージョンプロファイルが原因のエラー
今回のカスタムLambdaでは modelArn にクロスリージョン推論プロファイル(apac.* プレフィックス)を誤って指定していたため ValidationException が発生。
ValidationException: The provided model identifier is invalid.
クロスリージョン推論プロファイルは複数リージョンにリクエストをルーティングする仕組みのため、閉域VPC内では他リージョンへのアウトバウンド通信ができず使用不可。同一リージョンのモデルARNを直接指定が必要。
なおGenU標準のLambdaはクロスリージョン推論プロファイルを使っていないため、GenU側では発生しないエラー。今回はカスタムLambdaを新規実装した際に誤ったARNを書いてしまったことが原因。
# NG
model_arn = "arn:aws:bedrock:ap-northeast-1::foundation-model/apac.anthropic.claude-3-haiku..."
# OK
model_arn = "arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0"
USER_PASSWORD_AUTH と USER_SRP_AUTH の両方が必要
スクリプトからLambdaを直接テストするには USER_PASSWORD_AUTH、GenUのブラウザログインには USER_SRP_AUTH が必要。どちらか片方だけでは動かないケースがあるため、両方を有効化。
aws cognito-idp update-user-pool-client \
--user-pool-id <UserPoolId> \
--client-id <ClientId> \
--explicit-auth-flows "ALLOW_USER_PASSWORD_AUTH" "ALLOW_USER_SRP_AUTH" "ALLOW_REFRESH_TOKEN_AUTH"
PRIVATE_WITH_EGRESSサブネットが存在しない
通常のGenUデプロイでは PRIVATE_WITH_EGRESS サブネットが使われるが、閉域VPCにはIsolatedサブネットしか存在しない。CDKのLambda定義で PRIVATE_ISOLATED を明示的に指定が必要。
AgentCore RuntimeとBedrock Agentは別物
AgentCore RuntimeはGenUが生成AIエージェントを動かすための実行基盤で、Bedrock Agentとは別物。AgentCore Runtimeを使ったメタデータフィルタリングの実装は参考ブログの構成になり、今回の構成(カスタムLambda)とは別のアプローチ。
今回の構成の限界
カスタムLambdaのAPIはGenUのRAGチャット画面とは独立した構成のため、GenUのチャット画面からフィルタリング付きで使うにはAgentCore RuntimeにStrands Agentsでフィルタリングロジックを実装する方法が必要。
今回はあくまで「部署フィルタリングの仕組みが動く」という概念実証の位置づけ。GenUのチャット画面との統合は次回の検証テーマ。
まとめ
| GenU標準RAG | 今回の構成 | |
|---|---|---|
| 部署別フィルタリング | ❌ 全ドキュメントが対象 | ✅ 部署ごとに制限 |
| 実装コスト | なし | Lambda + API Gateway |
| GenU画面との統合 | ✅ | ❌(独立したAPI) |
次回はAgentCore RuntimeとStrands Agentsを使って、GenUのチャット画面からフィルタリング付きで使える構成を閉域で試す予定。
各機能の詳細解説
この記事で使った機能の仕組みを個別に掘り下げた記事も書いた。
- Bedrock Knowledge Baseのメタデータフィルタリング——フィルターの仕組み・構文・ハマりポイント
- retrieve_and_generate API——KB検索と回答生成を1回で完結させる仕組み