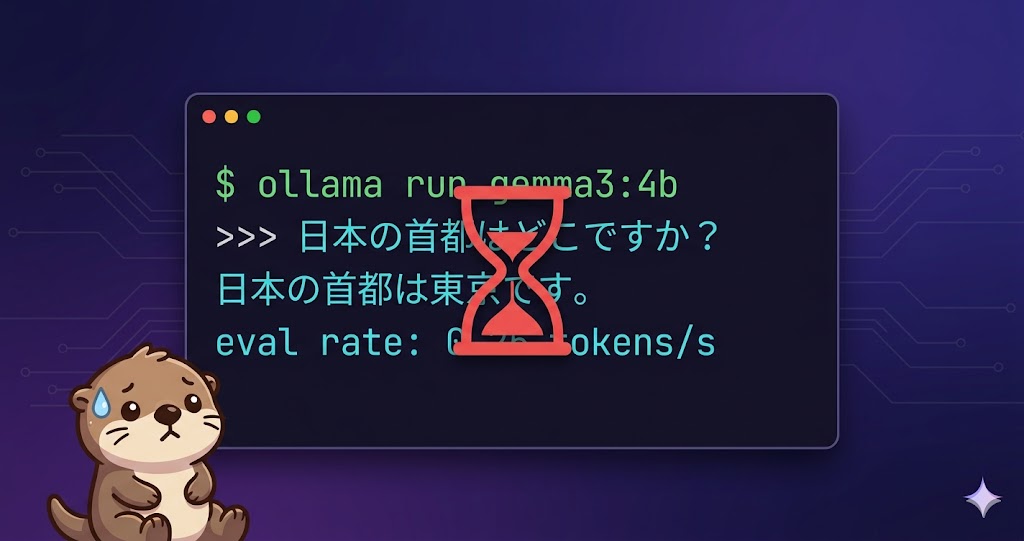
2026-03-14#Ollama#ローカルLLM#Gemma3#Mac#AIIntel MacにローカルLLMを入れてみたら思ったより遅かった話古いIntel MacにOllamaとGemma3を入れてみた。動くことは動く。ただし回答速度は0.25 tokens/secだった。ローカルLLMを試すなら何が必要か、実測値をもとにまとめた。続きを読む →